We live in a data-driven world, and SQL (Structured Query Language) is essential for managing data. SQL is used to manipulate and interact with data in a relational database. It’s used by businesses of all sizes, from startups to large corporations, to extract insights from their data and make informed decisions.
But writing SQL code is not just about knowing the language — it’s also about using best practices for coding and development. Poorly written SQL code can lead to performance issues, security vulnerabilities, and difficult-to-maintain databases. On the other hand, well-written code can make your database faster, more secure, and easier to manage.
This article will cover the best practices for SQL coding and development and provide practical, self-contained tips and techniques to help you write high-quality SQL code. With these best practices, you’ll increase productivity, optimize database performance, and ensure that your SQL code is secure and maintainable.
Prerequisites
Before diving into this tutorial, here are a few prerequisites you should be familiar with to help you get the most out of this article:
- Basic understanding of SQL syntax and data modeling.
- Familiarity with an SQL database management system (DBMS).
- Understanding of data normalization and normalization forms.
- Familiarity with a SQL client — DbVisualizer
These prerequisites are essential for creating well-designed databases that are optimized for performance and can handle a large amount of data. So, brush up on these prerequisites before diving into advanced SQL coding and development.
Effective Data Modeling
Effective data modeling is crucial for developing a database structure that is functional, maintainable, and scalable when it comes to SQL coding and development.
The following are some best practices for efficient SQL data modeling:
* To build a well-structured database, it’s essential to have a thorough understanding of schemas, tables, and columns. Schemas help to organize and group tables, while tables hold data that is organized in rows and columns. Understanding how columns interact with each other can help ensure data is stored correctly and efficiently.
To ensure proper usage, always follow best practices such as avoiding redundant data and designing tables with normalization principles in mind. Use descriptive and clear names for your schemas, tables, and columns that accurately represent their purpose. Additionally, avoid creating too many tables or adding too many columns to a table, which can lead to poor database performance.
For example, DON’T do this:
CREATE TABLE tbl_orders ( fld_order_id INT PRIMARY KEY, fld_customer_id INT, fld_order_date DATE, fld_total_amt DECIMAL(10,2) );Instead, DO this:
CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, total DECIMAL(10,2) );The second example follows best practices for naming and column usage, making it easier to understand and maintain the database. The first example uses ambiguous and abbreviated names, making it harder to understand and manage the database.
Proper data modeling and normalization are critical components of any SQL development project. Data modeling involves the process of designing the data structure that represents the business requirements. Normalization ensures that data is organized in a way that reduces duplication and improves data integrity. By following these best practices, developers can ensure that their databases are scalable, efficient, and accurate.
When designing a database, it is important to consider the relationships between the different entities and ensure that the data is normalized to reduce redundancy. Additionally, developers should choose appropriate data types and constraints to ensure that data is stored accurately and efficiently.
For example, DON’T store values of referenced entities like this:
CREATE TABLE orders ( order_id INT, customer_name VARCHAR(100), product_name VARCHAR(100), product_description VARCHAR(500), price FLOAT, quantity INT );Instead, DO this:
CREATE TABLE orders ( order_id INT, customer_id INT, product_id INT, order_date DATETIME, quantity INT, CONSTRAINT fk_customer FOREIGN KEY (customer_id) REFERENCES customers(customer_id), CONSTRAINT fk_product FOREIGN KEY (product_id) REFERENCES products(product_id) );
In the first example, there are multiple data fields, such as customer_name and product_description, that are not normalized and can lead to redundancy and data inconsistencies. In the second example, data is organized into separate tables and normalized, resulting in improved data integrity and efficiency.
When it comes to storing data in an SQL database, choosing the appropriate data types and constraints is crucial for maintaining data accuracy, consistency, and searchability. It is important to select the right data type to minimize storage space and reduce processing time. Constraints, such as NOT NULL and UNIQUE, help to ensure data integrity and prevent errors. By taking the time to choose the right data types and constraints, you can avoid unexpected issues with data quality down the line.
DON’T use vague or generic data types such as VARCHAR for all data types regardless of data size or use unnecessary constraints. For instance:
CREATE TABLE ExampleTable ( ID INT, Name VARCHAR, Email VARCHAR NOT NULL UNIQUE, Age INT, Address VARCHAR );Instead, carefully consider the data you will be storing and choose data types and constraints that are appropriate for the data’s size, expected use, and required accuracy. Use appropriate constraints such as NOT NULL and UNIQUE to ensure data integrity. For instance:
CREATE TABLE ExampleTable ( ID INT PRIMARY KEY, Name VARCHAR(50) NOT NULL, Email VARCHAR(255) NOT NULL, Age INT, Address VARCHAR(100) );Maintaining data integrity is essential to ensuring that the data in a SQL database is accurate and reliable. Constraints such as primary keys, foreign keys, and check constraints can help enforce rules for maintaining data consistency and integrity. Primary keys ensure that each record in a table is unique, foreign keys enforce referential integrity between tables, and check constraints limit the values that can be inserted or updated in a table. It is important to use these constraints correctly and consistently to prevent data inconsistencies that can lead to errors and other issues.
Here is an example of how NOT to use constraints to maintain data integrity:
CREATE TABLE Customers ( CustomerID INT, FirstName VARCHAR(50), LastName VARCHAR(50), Email VARCHAR(50), City VARCHAR(50), Country VARCHAR(50) );CREATE TABLE Orders ( OrderID INT, CustomerID INT, OrderDate DATE );
Instead, DO this:
CREATE TABLE Customers ( CustomerID INT PRIMARY KEY, FirstName VARCHAR(50) NOT NULL, LastName VARCHAR(50) NOT NULL, Email VARCHAR(50) UNIQUE, City VARCHAR(50) NOT NULL, Country VARCHAR(50) NOT NULL );CREATE TABLE Orders ( OrderID INT PRIMARY KEY, CustomerID INT, OrderDate DATE, FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) );
You can build a strong foundation for your SQL database by following these best practices, making it simpler to design, maintain, and scale your application.
Optimizing Performance
Poorly written queries and common mistakes can lead to slow response times and poor database performance. Optimizing SQL queries is essential for faster results and improved overall performance of your application.
Here are some best practices for optimizing your queries:
* The Performance Monitor feature in DBVisualizer helps you monitor the performance of your SQL database in real-time. This can help you identify slow queries, high CPU or memory usage, and other performance issues.
* Efficient SQL queries can significantly improve database organization. Avoid complex expressions, avoid subqueries, and make use of syntax best practices. Writing clear and concise code can help others understand it well and improve the overall organization of the database.
To illustrate this best practice, let’s consider an example of a query that fetches data from multiple tables. The wrong way to write the query is to use subqueries and a complex expression that involves multiple joins. For instance:
SELECT * FROM table1 WHERE id IN (SELECT id FROM table2 WHERE condition) AND name LIKE (SELECT name FROM table3 WHERE condition) AND value = (SELECT value FROM table4 WHERE condition) AND ... // more subqueriesA better approach is to use a join and write the query in a more straightforward way, like this:
SELECT t1.* FROM table1 t1 JOIN table2 t2 ON t1.id = t2.id JOIN table3 t3 ON t1.name = t3.name JOIN table4 t4 ON t1.value = t4.value WHERE t2.condition AND t3.condition AND t4.conditionBy avoiding subqueries and using simpler expressions, your queries are easier to understand and execute, resulting in better performance.
* Indexes are an important aspect of optimizing SQL query performance. They allow the database to efficiently retrieve specific data without scanning the entire table. When properly used, indexes can significantly improve the query response time. It is important to keep in mind that adding too many indexes can also have negative effects on performance as they require additional disk space and can slow down write operations.
Adding too many indexes requires more disk space and increases the overhead of maintaining the indexes during write operations, leading to slower performance.
To effectively use indexes, it is important to identify the columns that are frequently used in queries and create indexes on them. It is also important to use the correct type of index, such as a clustered or non-clustered index, depending on the situation.
When using indexes, consider using constraints like this:
CREATE INDEX idx_name ON table_name(column_name) WHERE column_name is not null;Instead of like this:
CREATE INDEX idx_name ON table_name(column_name);The first example is to beware of WHERE clauses finding NULL values.
* Testing and measuring the performance of SQL queries is essential in identifying bottlenecks and optimizing query execution. By testing queries with different data sets and measuring the response time, developers can determine the most efficient way to write the query. Measuring the query execution plan, utilizing query profiling tools, and monitoring resource usage can help pinpoint performance issues and identify areas for improvement. It is important to test the query under realistic conditions and consider all possible scenarios to ensure optimal performance.
For example, if the column after WHERE is indexed, the query performance is better:
SELECT * FROM customers WHERE customer_id = 123Instead of scanning through the rows like this:
SELECT * FROM customers WHERE customer_name = 'John' AND customer_address = '123 Main St'The first query uses an index to retrieve the data for a specific customer, resulting in better performance. The second query requires a full table scan to find the matching rows, resulting in poor query performance.
DBVisualizer provides an Explain Plan feature that allows you to analyze the execution plan of a query. This feature helps you identify potential bottlenecks and optimize the query for better performance.
Querying Techniques
Any SQL developer must possess the fundamental skill of querying data from an SQL database, and they can use various techniques to create efficient and effective queries. Writing efficient SQL queries is essential for optimizing database performance. Here are some best practices to follow:
* Understand SQL expressions and operators: SQL developers must understand SQL expressions and operators as they form the basis for writing effective queries. SELECT, FROM, WHERE, and JOIN are some of the commonly used SQL expressions and operators that every SQL developer must be familiar with. By understanding these expressions and operators, you can write queries that are optimized for performance and accuracy.
When constructing SQL queries, it is important to use the correct syntax and avoid overcomplicating the query unnecessarily. This can have a negative impact on performance and produce unexpected results.
* Write queries with simple logic: Writing queries with complex logic can be challenging, but breaking them down into smaller, more manageable chunks can make the process easier. Utilizing temporary tables or views can also help simplify the query and make it more efficient. It is also important to use proper syntax and formatting to ensure that the query is readable and understandable for others who may need to work with it in the future.
Avoid writing queries with complex logic that looks like this:
SELECT * FROM sales WHERE date >= '2022-01-01' AND date <= '2022-12-31' AND customer_id IN ( SELECT id FROM customers WHERE age >= 18 AND age <= 35 ) AND product_id IN ( SELECT id FROM products WHERE category = 'Electronics' AND price <= 1000 );Instead, make your queries less complex:
WITH temp_table AS ( SELECT id, SUM(sales) AS total_sales FROM sales GROUP BY id ) SELECT * FROM temp_table WHERE total_sales > 1000;In the above example, the second code demonstrates the use of a temporary table to simplify a complex query, while the first code shows a query with complex logic written without breaking it down into smaller chunks or using temporary tables.
* Utilize query parameters: Using query parameters in your SQL queries adds an additional layer of security and flexibility to your application. Instead of embedding values directly into the SQL query, which makes it susceptible to SQL injection attacks, consider using placeholders to represent the values that will be used at runtime. Query parameters also make it easier to reuse queries with different inputs, reducing the need for multiple, similar queries.
To use query parameters, you can specify placeholders in your SQL query and provide the values at runtime using a programming language interface.
DON’T embed values into queries like this:
# Unsafe: Directly embedding values into the query import sqlite3 conn = sqlite3.connect('example.db') c = conn.cursor() name = "John" age = 25 c.execute("SELECT * FROM users WHERE name='%s' AND age='%s'" % (name, age))Instead, DO this:
# Safe: Using query parameters import sqlite3 conn = sqlite3.connect('example.db') c = conn.cursor() name = "John" age = 25 c.execute("SELECT * FROM users WHERE name=? AND age=?", (name, age))Using the `?` placeholders and passing the values as a separate tuple ensures that the query is safe from SQL injection attacks.
By following these best practices, you can write efficient and effective SQL queries that will help your database perform optimally.
Additionally, consider using SQL performance monitoring tools (SQL Monitor, SolarWinds Database Performance Analyzer, SQL Sentry, Quest Foglight for SQL Server, or Redgate SQL Monitor) to identify slow or inefficient queries and optimize them for better performance.
Formatting and Style
In SQL coding and development, formatting and style are just as important as the code itself. Writing readable code can improve how quickly you can write and debug your code and how easily other team members can understand and collaborate on your code.
Here are some best practices for formatting and style:
* Naming conventions: Proper naming conventions and comments can help other developers understand your code’s purpose, making it easier to maintain and debug. Using consistent naming conventions helps to avoid confusion when working on projects with multiple team members.
When naming tables in SQL, DON’T do this:
SELECT * FROM customerTable cDO this instead:
SELECT * FROM customers c* Commenting: Commenting on your code can help future developers understand the reasoning behind specific decisions or logic. For instance, if a variable or column name does not make sense to someone else, they can refer to the comments to gain a better understanding.
When commenting on your code, DON’T do this:
--get data SELECT * FROM orders o WHERE o.customer_id IN (SELECT customer_id FROM invoices WHERE status = 'pending')DO this instead:
--get orders for customers with pending invoices SELECT * FROM orders o WHERE o.customer_id IN (SELECT customer_id FROM invoices WHERE status = 'pending')Or use multiple lines comments like this:
/* ….. get orders for customers with pending invoices */ SELECT * FROM orders o WHERE o.customer_id IN (SELECT customer_id FROM invoices WHERE status = 'pending')* Indentation and white spaces: Proper indentation and white spaces are crucial for creating readable SQL code, particularly when working with complex queries. Neglecting to format your code correctly can result in confusion and errors, making it challenging to debug and maintain. It is essential to establish consistent formatting practices across your team to ensure that everyone can understand and work with the code efficiently.
Avoid writing queries inline for readability, for example:
SELECT * FROM my_table WHERE my_column='value'DO this instead:
SELECT * FROM my_table WHERE my_column = 'value';
Correctly formatted code makes it easier to read and understand complex queries. In the example above, the second query is properly formatted, making it easier to identify each clause of the statement. The use of consistent indentation and white spaces ensures that each clause is distinct, making it easier to read and understand.
* Consistency with team guidelines: Establishing and following consistent formatting and style guidelines across team members can help prevent errors and make collaboration more efficient.
So, whether you’re working solo or collaborating with a team, mastering the art of readable code is essential for successful SQL coding and development.
The SQL Commander is a feature in DBVisualizer that allows you to write and execute SQL queries. You can use this feature to practice writing queries with complex logic, using the correct syntax and expressions, and optimizing performance with indexes.
Here is a screenshot of the SQL Commander, showing a properly written SQL query and the result:
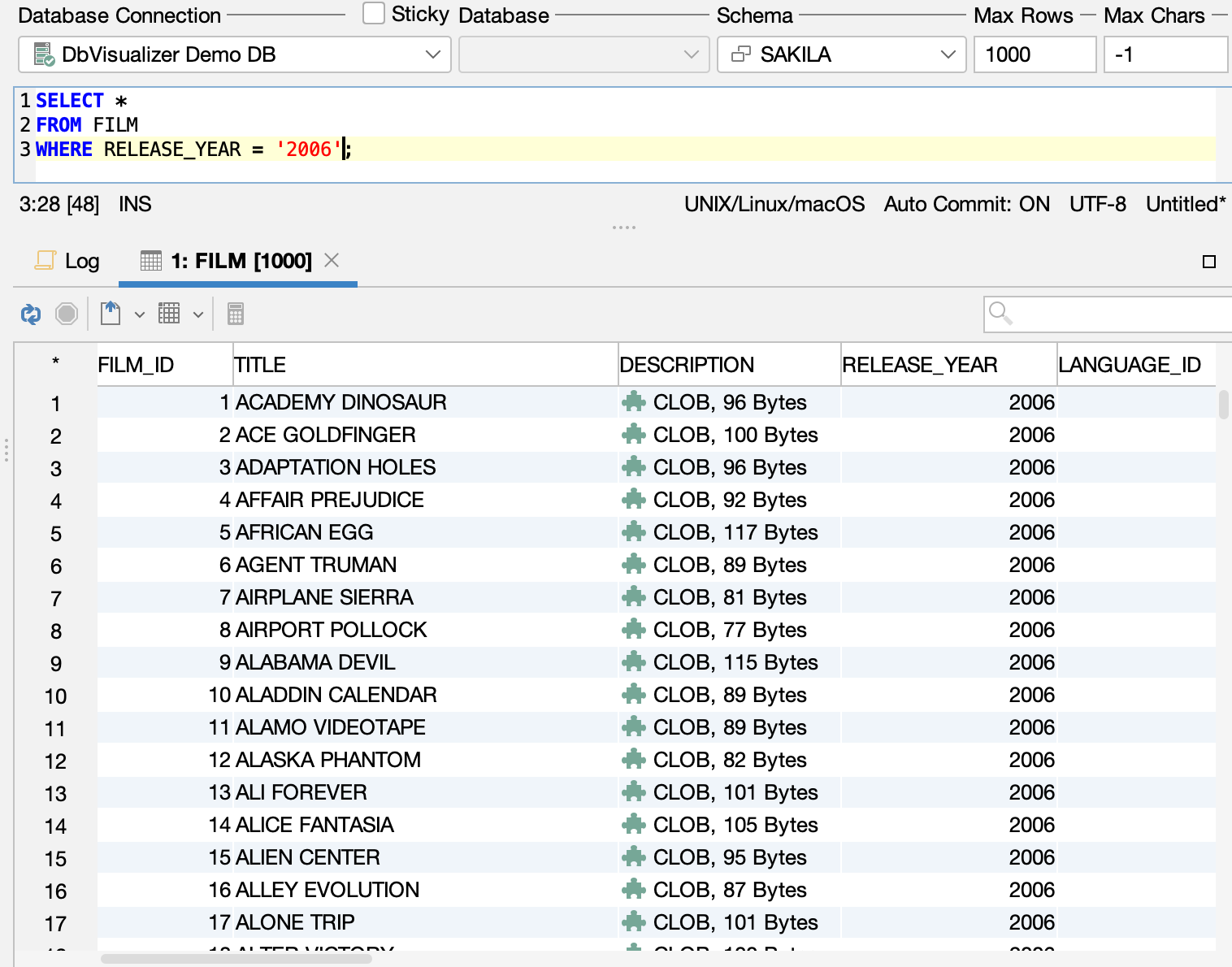
Screenshot of SQL commander
Conclusion
As you conclude reading this article on best practices for SQL coding and development, it’s crucial to keep in mind the key takeaways we discussed. From formatting and style to data modeling and querying techniques, these practices are fundamental to creating efficient, readable, and secure code.
However, the journey doesn’t end here. Continuous learning and keeping up with the latest best practices are crucial for any SQL developer. Attending training sessions, workshops, and conferences can help you gain new knowledge and stay current.
DBVisualizer is a powerful tool that can assist you in implementing these best practices. With its easy-to-use interface and a wide range of features, you can optimize your SQL coding process and enhance your database performance.
In today’s data-driven enterprise ecosystem, good SQL coding practices cannot be overemphasized. Efficient and secure databases are critical to business success, and implementing these best practices can help you achieve that. Start using DBVisualizer today to streamline your SQL coding process and take your database performance to the next level.