In its analysis of over 1,400 use cases from “Eye on Innovation” in Financial Services Awards, Gartner found that machine learning (ML) is the top technology used to empower innovations at financial services firms, with operational efficiency and cost optimisation as key intended business outcomes.
ML is a branch of artificial intelligence (AI) that involves the development of algorithms and models capable of automatically learning and improving from data. It empowers computers to identify patterns, make predictions, and take data-driven actions, enabling them to perform complex tasks and make decisions without explicit human intervention.
As the finance industry continues to embrace the power of ML, it is crucial to understand its use cases and challenges, as well as software ecosystems that are fueling its growth.
This blog provides a brief overview of ML in the finance industry and highlights some of the mature and evolving ML use cases that are having a transformative impact in the space. The blog then focuses on challenges enterprises face when scaling up initiatives and discusses how open source can enable financial institutions to harness the full potential of ML through streamlined model deployment and management.
Applications of machine learning in finance
The finance sector has a rich and extensive history with AI dating back to the early 1980s. In 1982, Apex created PlanPower, an AI program for tax and financial advice offered to clients with incomes of over $75,000. In 1987, Chase Lincoln First Bank (now part of JP Morgan Chase), launched the Personal Financial Planning System. Shortly after, in 1989, FICO Score, a credit scoring formula based on a similar algorithm used by banks today, was released.
For decades, banks have been using machine learning techniques to detect credit card fraud. In 2014, the British fund manager, Man Group, began using ML to invest its clients’ money. In 2016, Bank of America launched its chatbot Erica, which was considered a milestone in customer interaction. In 2018, various financial institutions announced the development of recommendation systems.
More recently, The Bank of England (BoE) and Financial Conduct Authority (FCA) conducted a joint survey to better understand the current use of ML in UK financial services. One of the key findings of the survey was that ML is increasingly being adopted and respondents expect significant growth in the use of machine learning over the coming years.
The median respondent of the survey expects their number of ML applications to more than double over the next three years [Exhibit 1]. For banking and insurance the expected growth is bigger still, with firms in each sector expecting the number of ML applications to almost triple.
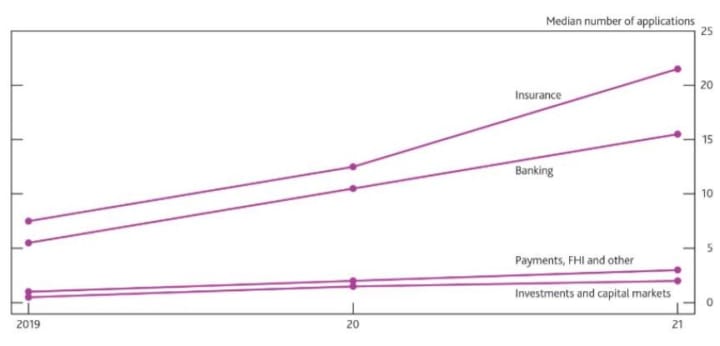
Source: BoE-FCA report
Machine learning has a broad range of use cases in the finance industry. Back-office functions, such as risk management and compliance have the most frequent use cases. These include anti-money laundering (AML) and fraud detection, as the need to connect large data sets and undertake pattern detection lends itself well to ML. However, ML is also increasingly being applied in front-office functions, like customer management, sales and trading. These use cases are made possible through different types of algorithms.
Learning types and algorithms explained
Let us look at some of the popular machine learning algorithms used in the finance industry according to learning types.
Supervised learning
This learning process is based on a set of known data previously tagged by an expert whose analysis helps define the new information. A way to do this is through classification, which allows new data to be assigned to different categories. Another method is regression, which relies on known information to predict certain behaviours or outcomes. Both regression and classification methods can be developed through decision trees.
Supervised machine learning algorithms are widely used in the finance industry for a variety of applications, as detailed in the tables below.
| Use case | Description |
| Credit Risk Assessment | Assess credit risk by predicting the likelihood of loan default. Models can be trained on historical data of borrowers, including their credit history, income, and other relevant features, to determine creditworthiness. |
| Fraud Detection | Identify fraudulent activities by learning from labelled data that includes both legitimate and fraudulent transactions. This enables financial institutions to detect suspicious behaviour and prevent potential fraud. |
| Customer Churn Prediction | Predict customer churn by training models on historical customer data, including their interactions with the company and previous churn instances. This helps businesses identify at-risk customers and implement retention strategies. |
| Market Price Prediction | Forecast stock prices, currency exchange rates, and other financial instruments by learning patterns from historical market data and relevant indicators. |
| Customer Segmentation | Segment customers based on their preferences and behaviours, allowing financial institutions to target specific groups with tailored marketing campaigns. |
| Regulatory Compliance | Supervised learning algorithms can aid in regulatory compliance by identifying potential violations, ensuring adherence to financial regulations. |
| Personalised Financial Recommendations | Provide personalised financial recommendations, such as investment strategies, based on individual customer profiles and risk tolerances. |
Unsupervised learning
This process uses unlabeled data, meaning no target variable is set and the structure is unknown. A subcategory of this is clustering, which consists of organising the available information into groups (“clusters”) with differential meanings.
A frequently used algorithm is “K-means” clustering, which establishes a fixed number of groups in a data set and assigns the information to each of them according to their proximity on a graphical representation. An example of learning by clustering is the creation of a set of consumer segments based on individual data, such as demographics, preferences, or purchasing behaviour. Another procedure is dimensionality reduction, which limits the number of input variables or dimensions of the feature set.
Below are some of the finance use cases that use unsupervised learning:
| Use Case | Description |
| Anomaly Detection | It can identify unusual patterns in financial transactions or market behaviour that may indicate fraudulent activities, insider trading, or abnormal market trends. |
| Portfolio Diversification | Assist in portfolio optimisation by clustering assets with similar risk and return characteristics. This helps in diversifying the portfolio and managing risk effectively. |
| Personalised Financial Recommendations | Unsupervised learning algorithms like K-Means clustering can group customers based on their behaviour and preferences, enabling targeted marketing strategies and personalised financial services. |
Reinforcement learning
In this learning method, the algorithm learns by interacting with its environment through the process of trial and error. Some of the finance use cases of reinforcement learning are:
| Use case | Description |
| Algorithmic Trading | Design trading strategies that maximise returns over time. Agents learn from historical market data and financial indicators to make trading decisions. |
| Optimal Execution | Optimise the execution of large trades by minimising market impact and transaction costs. |
| Risk Management | Model and manage financial risks by making decisions that consider potential risk exposure and reward. |
| Options Pricing | Calculate optimal options pricing in dynamic markets, considering factors such as volatility and market sentiment. |
Enterprise challenges of deploying ML at scale
As the number of ML applications in the finance industry grows, financial institutions will achieve efficiency gains and cost savings relative to traditional techniques. They will also gain benefits from better product personalisation for customers, new analytical insights and improved services, all of which are revenue-generating.
Despite this potential, financial institutions face challenges in realising the tangible advantages of implementing ML at scale. The key constraints to large-scale ML deployment faced by financial firms are legacy systems that are not conducive to ML, lack of access to sufficient data and difficulties integrating ML into existing business processes.
The potential risks include security and scalability of ML infrastructure and application ecosystems, model explainability, inaccurate predictions, data quality, biased data and algorithms. These risks can have a negative impact on consumers’ ability to use products and services, or even engage with financial institutions. This can, in turn, damage the firm’s reputation and lead to operational costs, service breakdowns and losses.
Can open source machine learning tools help address enterprise challenges?
When combined with MLOps (machine learning operations) practices, open source tooling can address the potential risks and challenges of large-scale ML deployment in the finance industry through various mechanisms. MLOps help firms overcome some of the common hurdles faced when implementing ML at scale, by providing a systematic approach to taking ML models to production, and maintaining and monitoring them.
- Security and scalability of ML infrastructure: Open source ML frameworks like TensorFlow, PyTorch, and Scikit-learn have active communities that continually review and address security vulnerabilities. Embracing an open source approach enables developers to contribute security enhancements and fixes, making the ML infrastructure more secure and scalable over time.
- Model explainability: Open source ML libraries often provide tools and techniques for model explainability, enabling financial institutions to interpret and understand the decisions made by ML models. Transparency in model behaviour helps build trust with regulators, stakeholders, and consumers.
- Accuracy and data quality: The collaborative nature of open source allows developers and data scientists to collectively identify and fix issues related to model accuracy and data quality. By sharing knowledge and best practices, ML models can be continuously improved for better accuracy and reliability.
- Bias mitigation: Open source ML frameworks can integrate fairness-aware algorithms that help identify and mitigate biases in models and data. The open community can work together to develop techniques that promote fairness and prevent biased decision-making.
- Data quality and governance: Open source ML encourages best practices in data governance, documentation, and validation, ensuring that data used for training is of high quality and complies with regulatory standards.
- Cost-effectiveness: Open source ML frameworks significantly reduce the cost of large-scale ML deployment, making it accessible to a broader range of financial institutions. This cost-effectiveness enables organisations to invest in other areas of ML implementation, such as data quality and model validation.
By using open source ML tools and platforms, financial institutions can tap into a vast pool of expertise and knowledge, reducing the burden of addressing risks and challenges in isolation. Open source encourages transparency, collaboration, and shared responsibility, which are essential factors in building robust and trustworthy ML solutions in the finance industry.
The Canonical open source MLOps stack
For financial institutions to reap the rewards of their ML efforts, models must be developed within a repeatable process using an MLOps platform that empowers data scientists to manage the end-to-end ML process efficiently.
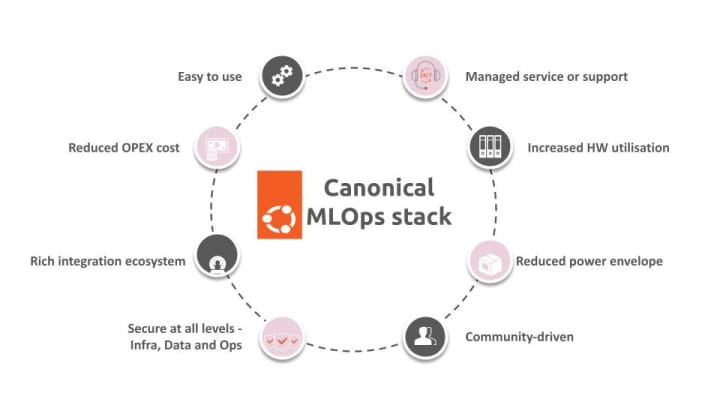
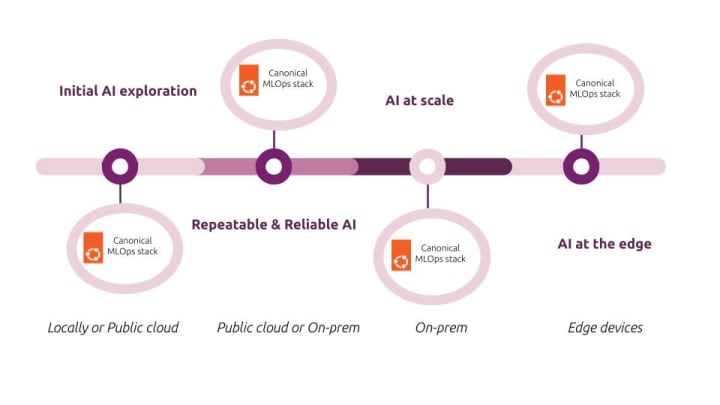
Ubuntu and Canonical’s open source MLOps stack [Exhibit 2] provide a seamless and versatile platform for financial institutions to explore, deploy, and scale AI/ML workloads across different environments. From initial AI/ML exploration to developing repeatable and reliable AI solutions on public cloud or on-premises infrastructure, Canonical’s MLOps stack facilitates the entire lifecycle [Exhibit 3]. The stack includes a wide range of tools and services, enabling data scientists and engineers to experiment with cutting-edge machine learning algorithms and frameworks.
Kubeflow, an open source MLOps platform can be used by firms to develop and deploy scalable ML systems. For financial institutions, ensuring the secure management of open-source software and its dependencies is critical. This holds especially true for an open source MLOps platform, where building and maintaining AI/ML-powered intelligent applications must align with stringent compliance, security, and support requirements.
For financial institutions looking to adopt ML at scale with a secure open source MLOps platform, Canonical offers Charmed Kubeflow and Ubuntu Pro.
Charmed Kubeflow is an enterprise-ready and fully supported end-to-end MLOps platform for any cloud. Charmed Kubeflow users can sign up for Canonical’s Ubuntu Pro subscription to get timeline security patches for Charmed Kubeflow and for all the packages in Ubuntu’s Main and Universe repositories, which include many popular open source data engineering toolchains.
Want to learn more about secure open source for financial services? Read our white paper
Deliver ML at scale for your financial services company with secure open source
Get in touch
Photo by Morgan Richardson on Unsplash