With the ever-increasing amount and variety of data, constantly growing regulations and legislation requirements, new capabilities and techniques to process the data, to become a data-driven organization, CIBC goes through enormous changes in all aspects of leveraging, managing, and governing the data.
To address the requirements of this new reality, CIBC embraced the data mesh paradigm and developed a generic two-part data pattern. On the business side, the pattern introduced a data product strategy to define data domains and data products end-to-end owned by the cross-functional data product teams. On the technology side, CIBC has implemented a data mesh architecture to support the data product strategy. The central part of this architecture is represented by a data management platform providing a shared platform and data management and governance services. The article introduces and discusses guiding principles driving the data strategy.
The data strategy, defined by the data pattern, allows for a combination of clear data ownership, self-service, and business teams’ autonomy under centralized governance to define and enforce data management and security policies and standards while providing high-quality data in a timely manner to facilitate proper business decisions.
The article explains why the new data strategy represents a transformational shift, requiring organizational, cultural, and behavioral changes. To support the shift, new incentives and well-defined KPIs are required. The paper discusses and proposes such incentives and provides recommendations regarding the KPIs.
The paper also performs an analysis of the factors contributing to the success of the data strategy implementation. It’s shown that proper definition and governance of the data products across the organization is critical for the implementation success. The data migration initiatives across the organization must be carefully coordinated to properly realize the data product strategy, avoid data duplication, save on resources, and implement the strategy in the most cost-effective way.
Finally, the paper stresses importance of the education across the organization to facilitate the transformational shift and empower the organization with the required knowledge and skills to implement the strategy.
Who Are We?
Canadian Imperial Bank of Commerce (CIBC) is a major Canadian Bank with more than 150 years of history. The technology landscape is highly heterogeneous, including everything from mainframe to modern appliances, from legacy applications to services exposed through modern APIs, from all types of databases, including appliances, to centralized enterprise data hubs.
Drivers for Change
The data landscape significantly changed over the last decade. New functional and non-functional requirements emerged. The following defines major drivers for change:
- The data has been changing: The 3Vs (volume, variety, and velocity) are three defining properties or dimensions of big data. Volume refers to the amount of data, variety refers to the number of types of data, and velocity refers to the speed of data processing.
- Regulations and legislation: Ever-increasing requirements for regulatory reporting and auditing, data lineage, and privacy legislation lead to the complexity of data governance, which stipulates the requirements for governance automation.
With exponential growth of data volume and ever-increasing business and regulatory requirements, in order to remain competitive, CIBC’s Data Strategy and Data Architecture need to innovate – and fast.
Future State
The main idea is to move the responsibility for the data to the people who are closest to the business function and understand the data and related business logic. This is how data mesh was born. The data mesh combines clear data ownership, self-service, and business teams’ autonomy under centralized governance to enforce data management and security policies and standards. The major problems data mesh solves are:
- Ownership clarity: The data product team will own the data end-to-end.
- Data quality: The data product team is responsible for the data quality.
- Data agility: The data product team will own the data pipeline end-to-end with minimum dependency on the central team. This autonomy will allow the team to faster react to new and/or changing business requirements.
Data Strategy
Data Strategy consists of two major parts:
1. Data Product Strategy
On the business side, we introduced a Data Product strategy to define data domains and data products across the organization and move the responsibility for the data to the people who are closest to the business function and the data domain. The data products definition is technology and applications agnostic. The data product will be end-to-end and managed by a data product team. Each data product must expose well-defined interfaces to share the data with the rest of the organization. Data products must be discoverable and addressable.
2. Data Mesh Architecture
On the technology side, the strategy introduces Data Mesh architecture to enable the data product strategy and allow data product teams to manage their data under centralized governance to enforce data management standards and policies. The critical part of the data mesh architecture is the Management Platform and Services (MPS), which provides two major sets of capabilities. The first part represents platform services, which provide a kind of abstraction layer over the complexity of the Azure resources to allow data product teams to instantiate and run their data products without necessarily deep knowledge and understanding of how it works under the hood. The second part provides data management and data governance capabilities, including, but not limited to, data catalog, data marketplace, metadata management, data lineage, and centralized rules. The rules capture the requirements of the data management and security standards, which should be available to the data products to enforce the rules in run-time on the data nodes.
Guiding Principles
Guiding principles define the underlying rules and guidelines to develop, implement, and deploy strategic architecture and related solutions across the organization.
|
Guiding Principle |
Description |
|
Enterprise Data Management requirements must be embedded within the pattern. |
The pattern must assure that the requirements can be centrally captured in the form of centralized rules and available to the execution environment to enforce the rules. |
|
The Pattern must be technology and tools-agnostic. It’s not prescriptive regarding the technology products and a solution. Technology will be selected by the data domains teams and driven by use cases. |
It allows architecture and development teams to choose a technology that mostly fits the use-case requirements. The technology and tools must be certified by cloud engineering for use in the CIBC environment. |
|
Data access policies and governance should be datacentric to enable consistent enforcement of policies rather than based on the applications, storage systems, or analytics engines. |
Any piece of data must have associated metadata describing the nature of the data, confidentiality, etc. The metadata will dictate the security controls which must be implemented across all data products regardless of their scope and business logic. |
|
Leverage data virtualizations, taking steps toward connecting data rather than collecting data, to minimize the data movement and reduce replication and collection data, where applicable |
Data virtualization allows us to connect to data rather than move them. Virtualization imposes certain requirements for the data provider in terms of availability, performance, etc. The use cases must be carefully evaluated to determine if virtualization is the right approach for these use cases. |
|
Leverage compute-storage separation pattern. |
The pattern decouples compute environment from storage to allow scaling out compute environment or increasing storage capacity independently of each other. |
|
Promote data reusability to avoid data duplication, where applicable |
One and only one source-aligned data product on the data mesh serves as a trusted source of data for certain business domains. |
|
Enable self-service data discovery and data consumption for business users |
Data products must be published and available for consumers to search and browse. Metadata published with the data products must include technical, business, and operational details, including data classifiers and schemas, and be sufficient for self-service data consumption. |
|
The pattern should support different types of architecture, including, but not limited to, Lambda and Kappa architectures. |
The pattern is not limited to any particular architecture or data workflow. |
|
Data must be available through well-defined mechanisms for reporting and analytics across the organization. |
Data must be easily available to the rest of the organization through well-defined interfaces exposed by a data product defined as a single point of truth for the data. |
Who Owns a Data Product?
Source-aligned data products must be owned by a team that originates the data. It’s important to note that a data product must be owned by one and only one data product team. There are multiple scenarios in that one application in the organization holds data belonging to different business teams. For example, a business process management (BPM) system might manage and store data for different business processes, including mortgages, lines of credit, loans, etc. In this case, the data must be filtered out and ingested into the proper data product.
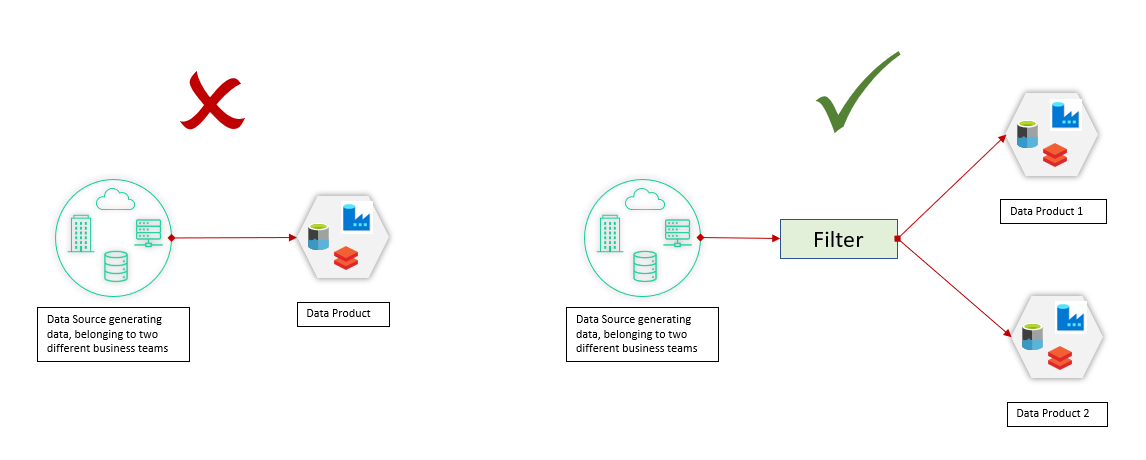
Figure 1: Source-aligned data product ownership
Aggregates are owned by the producer or consumer teams or a newly formed team. Consumer-aligned data products are usually owned by the consumer data product team.
Data Mesh Proof of Concept (POC)
Data Mesh is a fairly innovative approach. To demonstrate how Data Mesh can be used to provide a solution for real-life scenarios, CIBC, jointly with Microsoft, conducted a POC. The use case was greatly simplified, but it was good enough for our purposes.
Let’s say Imaginary Bank CEO wants to know the Deposit / Loan ratio to make the right business decision. The initial deposit and loan data produced by different systems across Retail and Commercial Banking LOBs. The data mesh allowed to collect the data, join the data, and produce required reports.

Figure 2: CIBC-Microsoft Data Mesh POC
The POC confirmed our assumptions regarding the data mesh and mapping of the logical constructs of the mesh to Azure technology. It was critical to define proper business rules to allow joint use of the data from different LOBs built on different data models. Using predefined Microsoft templates allowed us to greatly accelerate the solution and complete the POC in a fairly short period, overall end-to-end, about 1.5 months.
As stated by one of the guiding principles, the data pattern is technology and tools agnostic, meaning that it could also be implemented on top of the recently announced Microsoft Fabric.
Implementation Consideration
The CIBC data strategy is not a technological shift. It’s a transformational shift. When we are thinking about data migration to the cloud, it’s not about moving data from one technology to another. It’s not just a lift-and-shift of the data to the cloud. The data must be ingested into the right data products to avoid data duplication and assure data quality. A data product representing a certain business area becomes a single source of these data to consumers for reporting, analytics, and AI/ML. For example, just one and only one data product will provide customer data to the rest of the organization.
As in any large organization, there is some data duplication across CIBC applications. When moving the data to the cloud, we have to identify all the sources, consolidate the data from these sources, remove any duplication and ingest full-fidelity data to the properly defined data product.
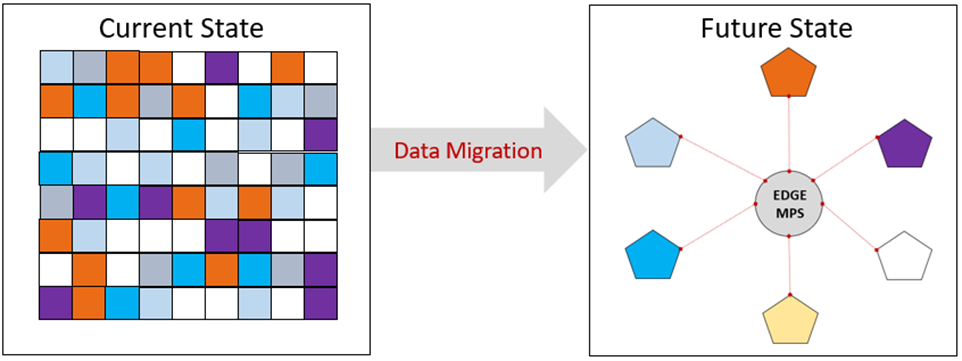
Figure 3: Data migration
That’s why it’s so important for any initiative involving data migration to start with defining the data products. If we are not moving data to the right data products, we can’t say we are moving data to the data mesh. Proper data product taxonomy is critical for the successful implementation of the data mesh.
How to Define Data Products
As stated above, the success of the data mesh implementation critically depends on the proper definition and construction of the data products. This is the most challenging part of the data mesh implementation. Why? Because this is new. Because this is a transformational change.
The Data Product definition states that a data product can be “potentially made up of multiple contributors.” What does it mean?
Let’s take as an example some business domains. Historically happened, there might be many applications in the organization which hold this domain data, depending on the lifecycle, for example, adjudication, transactions, payment, reconciliation, etc. Each of these applications deals with just a fraction of full-fidelity data. On the other hand, data analysts and/or data scientists most likely would be interested in a holistic view of the domain data rather than the fraction of these data stored by each of these applications. They would also need a mechanism to correlate and stitch the data together, as the data from different applications are defined by different data models.
We will call the data owned by a certain application a data asset. Each data asset is built on its own data model. One option here is to expose the data assets and put the burden on stitching these data assets on the consumers. In this case, every consumer will need to learn underlying data models, and the stitching will be done multiple times, depending on the consumption use cases. Instead, we suggest doing it just once, leveraging the data product data model illustrated in the diagram below.
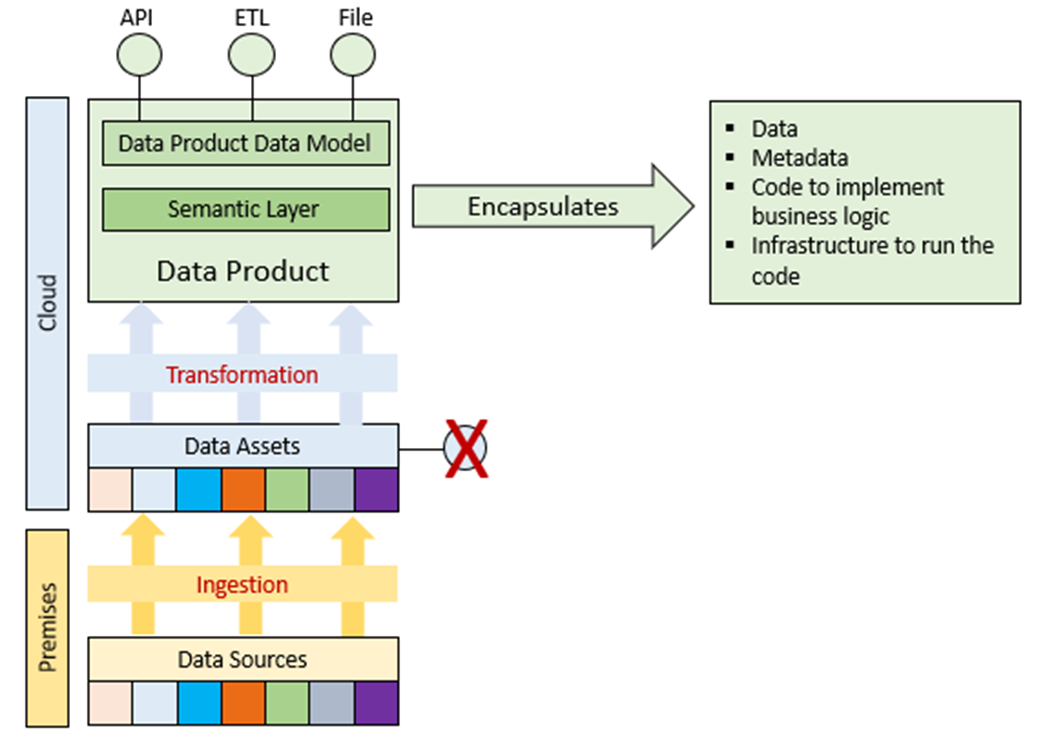
Figure 4: Composing data product
The data assets will be ingested into a data product. The data product must expose the data product data model. The data model is mostly driven by the business and must be technology and applications-agnostic. When stitching the data from different data assets, transformation must be performed from data assets data models to the data product data model.
To alleviate the burden of building the entire data model up-front, in some cases, the data model might be built and implemented incrementally, adding more data assets as required under the condition that it doesn’t compromise the quality of the target full-fidelity data model.
Data Product Definition Guidelines
We see a data product definition as a combination of a top-down/bottom-up approach. The top-down process starts with the business defining needs, requirements, and data models. The bottom-up process maps these requirements and models to the organization applications landscape to define the data sources.
Keep in mind that it’s not black-and-white. It could be a complex iterative process, a kind of mix of art and science. The approach might need to be adjusted depending on use cases and data types.
Top-Down: Define Data Products
This process is mostly business driven. It should be technology and applications agnostic. The major steps are:
- Business defines a need for data in certain business areas for analytical purposes.
- The business provides high-level requirements.
- Establish data domain/data product governance team. The team might be expanded in the later stages.
- Develop a data model for the data domain. The data model might be developed from scratch for a new business area, derived from the existing data warehouses using reverse engineering or using a combination of these techniques.
- Identify data model tables related to the same business function. Most likely, these tables will be mapped to the same data product.
- Define required source-aligned and aggregate data products.
- Define data products that might be required to fulfill the business function but are not owned by the business area and belong to and will be created by other data domains.
- Define data products that don’t exist and must be created.
Bottom-up: Define Applications/Data Sources
This process allows to specify data sources for the data products defined in the top-down process.
- Identify applications holding data defined by the Data Models.
- These applications will become data sources for the Data Products.
- Define required data transformations from application data models to data product data models.
- Data products will be exposed to the consumers through the data products’ data models.
How To Start?
Let’s say we have an initiative involving building an analytical environment or data migration to the cloud. How to start?
We suggest starting with the business. What business problem are you trying to solve? What data are required to solve the problem? What are the next steps?
The high-level recommended steps are:
- Centrally coordinated data migration is a must.
There might be some data duplication across the organization. Having multiple uncoordinated initiatives dealing with the data migration will inevitably result in duplication of the data and data products on the cloud.
- Data-driven approach rather than use-case driven.
- Start with the business. Define and prioritize high-level consumption use cases across the organization rather than focusing on the implementation of siloed initiatives. The use cases might be a high-level aggregation of the use cases defined by these initiatives.
- Choose the number of use cases of low to medium complexity, preferably in the same business area. The number might be limited by the available resources, such as data modelers, data product developers, etc. Ideally is to start small with just one or two use cases.
- Define data required for the use cases.
- Define required data products following the top-down/button-up approach. Some of these data products might already exist. Gradually, you build the data product backlog and need to prioritize the data products for implementation. Going forward, more and more data products will be available on the mesh, and the initiatives will be focused mostly on implementing functionality and consuming data from existing data products.
- Define data sources to create and populate new data products
- Implement functionality of the selected use cases leveraging created data products. The functionality might be implemented as part of the existing or new consumer-oriented data products.
- As the maturity of the data products portfolio increases, the use cases might be re-prioritized, and more complex use cases could be selected for implementation.
- Start a new cycle with a).
- Must be supported by governance and operational model. Governance should focus on aspects across data domains, including prioritizing and approving new data products.
Design Principles
The service design principles introduced are still very valid and highly applicable. Most of them directly translate to data product qualities:
- Standardized Service Contract: Data products are exposed to the rest of the organization through a unified data product data model.
- Service Reusability: Data products are shared across the organization through well-defined secure interfaces.
- Service Discoverability: Data products must be discoverable.
- Service Composability: Source-aligned data products could be aggregated to compose new aggregate data products.
- Service Abstraction: The data product data model is visible to consumers, but not the data product implementation details.
- Service Autonomy: The data product includes data, metadata, business logic, and the infrastructure to run the logic.
- Service Loose Coupling: The principle states, “Service contracts impose low consumer coupling requirements and are themselves decoupled from their surrounding environment.” It covers multiple types of loose coupling, i.e., decoupling interfaces from service implementations, decoupling service consumers from service providers, and having services “themselves decoupled from their surrounding environment.” In other words, it also means decoupling business logic from the services provided by the platform and/or Cloud Service Provider (CSP). This is also best practice widely recommended and used in the industry. Many frameworks allow customization, which can be used to implement business logic, but this should be considered a bad practice. There are a number of reasons for this recommendation; one of them is a vendor lock. Decoupling business logic from the services provided by Cloud Service Provider (CSP) paves the way to multi-cloud data architecture.
How To Motivate Alignment to the Data Strategy?
Why the Incentives Are Required
As we already mentioned, successful data strategy implementation is not possible without massive transformational change. Both technological and organizational changes are required, complementing each other.
Technology alone cannot overcome organizational challenges:
- Renting, buying, or building a data mesh solution without necessary organizational changes won’t solve the actual data ownership, data quality, and data governance problems.
- Just building data lakehouse(s), and introducing data governance tools, won’t solve the data quality and data agility problems.
Organizational changes are not possible without supporting technology:
- Data product teams won’t be able to accept and exercise data ownership without supporting technology and proper tools.
- Data product teams won’ be able to build, instantiate, and run data products without self-serve infrastructure.
- Centralized governance is impossible without well-designed automation.
Transformational change is hard. That’s why additional incentives are required.
Incentives
Proper incentives must be developed and implemented across the organization to help the transformation happen, for example:
- Reward Data Product Teams by the usage of their data products rather than by the number of data products they produce.
- Reward Consumers for using approved data products instead of sourcing data directly from the data sources.
- Reward good, widely used data products
Meaningful KPIs
Key performance indicators (KPIs) should stem from real business problems, be aligned to strategic objectives and goals, and must be measurable. Meaningful KPIs should also stimulate the right data architecture decisions.
- The goal: Reduce Data Product creation time.
- How: Providing effective MPS services.
- It warrants 1st KPI: Lead time to create a data product.
- The goal: Improve Data Product time to production.
- How: Providing effective DevOps and data management processes.
- It warrants 2nd KPI: Lead time to production (time from development to production).
- Simple formula: (Work + Wait) / Work
- The goal: Assure data product timeliness.
- How: Effective data ingestion and data processing pipeline.
- It warrants 3rdKPI: Data product change frequency.
- 4th KPI: Data product change fails ratio.
- The goal: Assure data product availability.
- How: High availability and disaster recovery.
- It warrants the 5th KPI: Data product mean time to recovery.
- The goal: Data enablement
- How: Data discoverability and addressability through MPS Services.
- It warrants the 6th KPI: Lead time to find the relevant data.
Data Literacy
The data strategy moves data ownership and data processing to data product teams close to the business function. These cross-functional teams are composed of business, architecture, development, cloud engineering, and security representatives, as required. Eventually, most of the people dealing with data would become part of these teams or will be interacting with them. To perform their roles, they need to have a good understanding of the data strategy and acquire relevant technology knowledge to implement the strategy and the related patterns, depending on their roles.
A data literacy program is a must to have the proper resources to execute the data strategy. It might include presentations, workshops, and free and paid courses to help gain knowledge and equip all employees with the necessary skills required to be part of the transformational change.
Key Takeaways
- Canadian Imperial Bank of Commerce (CIBC) is a major Canadian Bank with more than 150 years of history. The data technology landscape is highly heterogeneous, from legacy mainframe applications, all types of databases, and appliances, to centralized enterprise data hubs (EDH).
- CIBC adopted a data mesh paradigm to develop a two-part data strategy:
- Technology agnostic data product strategy defines data domains and data products to move the responsibility for the data to the teams who are closest to the data function and understand the data and related business logic.
- Data mesh architecture enables data product strategy and allows data product teams to own and run their data end-to-end under centralized governance.
- The data mesh is about data ownership and data organization. It’s not just a technological shift from on-prem technologies to a cloud. It’s a transformational change involving organizational, behavioral, and cultural aspects.
- Microsoft Cloud Scaled Analytics allowed us to conduct and successfully complete POC for real-life scenarios quickly.
- Developed design principles directly translated from the service design principles introduced by services-oriented architecture.
- Transformational change is hard. Proper incentives and KPIs must be introduced to motivate the teams across the organization to accept the change.
- Data literacy and upskilling have to be part of the enterprise data transformation.