Optimizing the speed of a WordPress website is essential for ensuring a superior user experience and achieving higher rankings in search engine results. Slow…
For all intents and purposes, DNS can be considered almost like the internet’s phonebook. At least that’s how it’s most often metaphorically explained. However,…
As digital data becomes more prevalent, the protection of personal information has become a pressing issue. For website owners using the Drupal platform, ensuring…
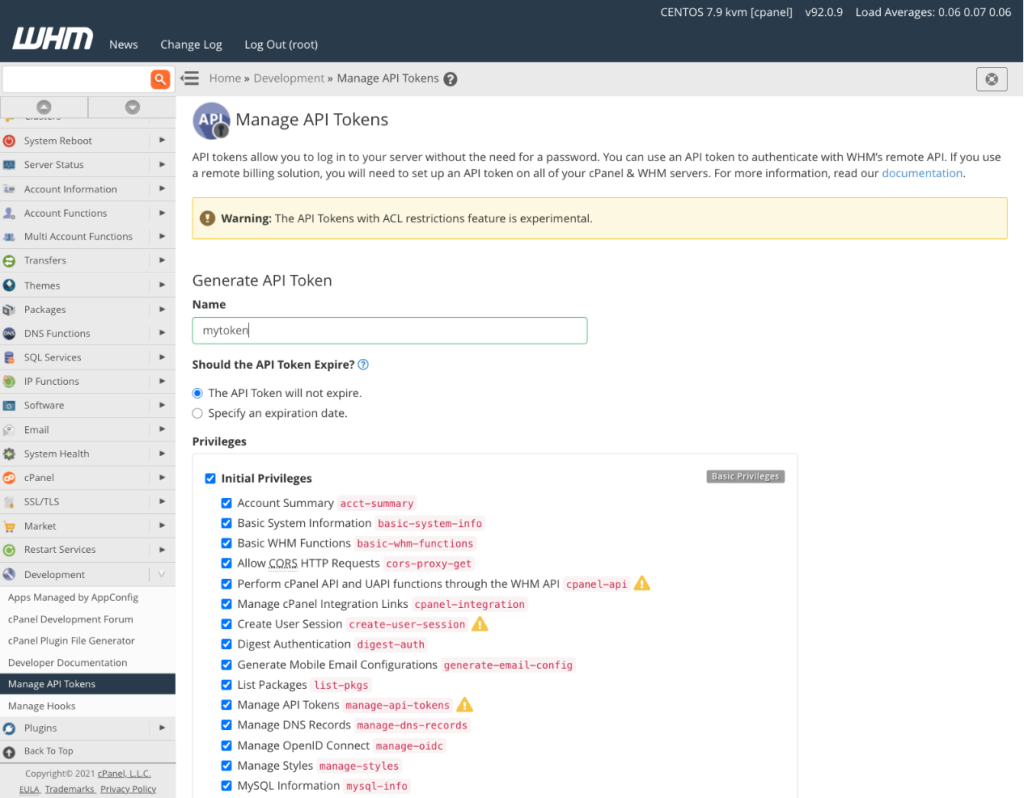
cPanel & WHM’s web interfaces offer a comprehensive server and web hosting management solution, but hosts and developers often want to automate tasks or…