
One of the buzz words around Netapp Ontap 9 is the new feature of data compaction. Working along side other storage efficiency mechanisms such as dedupe and compression, data compaction is able to further reduce your data foot print.
How does Netapp Data Compaction Work

Data Compaction is an inline process which takes I/O’s that would normally consume multiple 4K blocks and tries to fit it into one physical 4K block. This makes a lot of sense when you break down the 4K block and see how much data is actually consuming it. The actual data could only be consuming 25% of the 4K block so the 75% of the remaining block is kind of wasted.
If we take an example of the following three 4K blocks containing a certain percentage of data:
- 4K block – 25% data
- 4K block – 5% data
- 4K block – 60% data
With data compaction, we can compact the three blocks above into one 4K block that contains 90% data
The order in which the storage efficiency processes are executed are:
- Inline zero-block deduplication
- Inline adaptive compression
- Inline deduplication
- Inline adaptive Data Compaction
The most beneficial use cases for Data Compression are with very small I/Os and files (<2KB) and larger I/O’s with lots of white space.
It is supported on Netapp AFF (enabled by default), Flash Pool and HDD aggregates.
I’ve been able to test this in the lab with the Netapp Ontap 9 sim running an NFS datastore mounted to VMware 5.5.
Netapp Ontap 9 Data Compaction VMware Example
- I’ve created a new NFS volume called SVM1_NFS1 and mounted it to my VMware hosts
- I enable dedupe and inline compression on the SVM1_NFS1 volume
- Next I need to enable Data Compaction on the SVM1_NFS1 volume. To do this I type in:
- ::> volume efficiency modify -vserver SVM1 -volume SVM1_NFS1 -data-compaction true
- I then storage vmotion 2 Windows 2012 R2 virtual machines (total size 42GB) to the NFS datastore SVM1_NFS1
- During the storage vmotion I was looking at the compaction savings from within the CLI. To do this you type:
- ::> storage aggregate show -fields data-compaction-space-saved
- Once the storage vmotion completed I then ran a dedupe scan to get the rest of the space savings.
VMware Volume Efficiency Savings
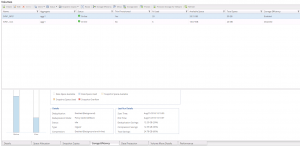
VMware Aggregate Data Compaction Savings

Netapp Ontap 9 Data Compaction SQL Example
Next we’ll look at the space savings on a different kind of workload, this time being Microsoft SQL. I have gone ahead and created a new aggregate called aggr2 and a new volume called SVM1_NFS2. This new volume has dedupe and inline compression enabled.
Within VMware I used storage vmotion to move the data disk containing all the SQL databases and log file to the NFS datastore called SVM1_NFS2. Once the storage vmotion completed, I then went ahead and ran a manual dedupe on the volume.
Below we can see the space savings on the SQL database workload
SQL Volume Efficiency Savings
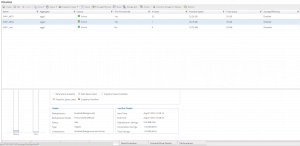
SQL Aggregate Data Compaction Savings
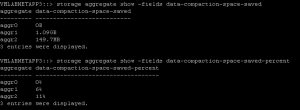
As we can see in the SQL Aggregate Data Compaction Savings, we are looking at nearly a 50% increase in compaction savings between VMware virtual machines and SQL Databases. Why you ask ? SQL Databases can contain a fair amount of white space, which is an excellent candidate for Data Compaction.
Netapp Ontap 9.1 Compacting existing Data
Starting from Netapp Ontap 9.1, it is now possible to compact existing data. The command to do this is:
volume efficiency start –vsever SVM1 -volume VOLUME1 – compaction true
Technical Reference 4476 – Netapp Data Compression, Deduplication and Data Compaction
The post Netapp Ontap 9 Data Compaction appeared first on SYSADMINTUTORIALS IT TECHNOLOGY BLOG.

